
【Python】ハッシュ法とチェイン法【アルゴリズム】
Pythonでアルゴリズムのハッシュ法とチェイン法の解説をします。
ソート済み配列への要素の追加
要素数が13個の配列xがあるとします。
配列xには4、10、19、25、37、44、53、68、73、85という10個の要素がすでに昇順で格納されているとします。
この配列xに61を追加することを考えます。
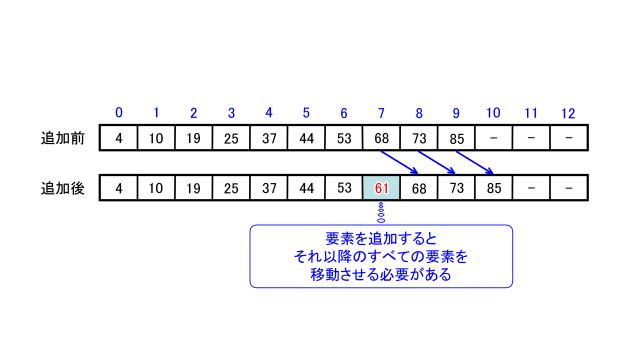
2分探索法によって解くと以下のようになります。
| ① | 2分探索法によって x[6]とx[7]の間に 挿入すべきだとわかる。 |
|---|---|
| ② | x[7]以降のすべての要素を ひとつ後方にずらす。 |
| ③ | x[7]に61を代入する。 |
確かにこの方法でもできますが場合によってはかなりのコストになります。
仮に削除するとなると今度は以降のすべての要素を前方に移動させなければなりません。
探索だけでなく追加や削除も効率よくできるのがハッシュ法です。
ハッシュ法
ハッシュ法(hashing)は演算によって求めた配列の添え字の位置にデータを格納できるアルゴリズムです。
線形探索や2分探索法と違い探索だけでなく追加や削除も行えます。
同じ配列xに61を追加することをハッシュ法で考えます。
| キー | 4 | 10 | 19 | 25 | 37 | 44 | 53 | 68 | 73 | 85 |
|---|---|---|---|---|---|---|---|---|---|---|
| ハッシュ値 (13で割った 剰余) |
4 | 10 | 6 | 12 | 11 | 5 | 1 | 3 | 8 | 7 |
配列の各要素の値(キー)を適切な数で割った剰余(あまり)をハッシュ値といいます。
今回は配列の要素数13で割りましたがそれ以外の値でも可能です。
ハッシュ値を添え字にして対応するキーを格納した配列をハッシュ表といいます。
例えば53を13で割った剰余は1なのでハッシュ表では添え字1にキー53を格納します。
なおハッシュ表の各要素のことをバケット(bucket)といいます。
ここではハッシュ表を表す配列をaとします。
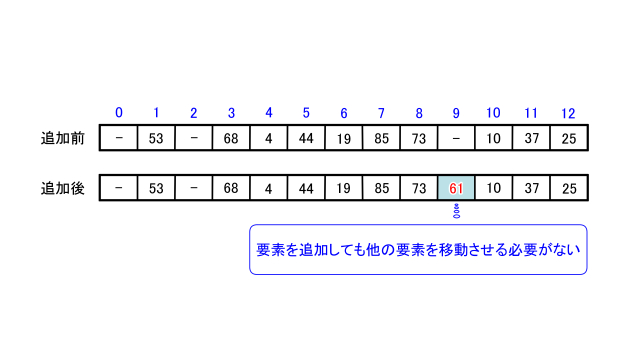
追加したい値61を13で割った剰余は9なので、a[9]に格納します。
2分探索法を使った時のように他の要素を移動させる必要はありません。
このように剰余を求めるなどしてキーからハッシュ値に変換する流れをハッシュ関数といいます。
衝突
今度はハッシュ表aに45を追加することを考えます。
45を13で割った剰余は6となります。
しかしバケットa[6]にはすでに19が格納されています。
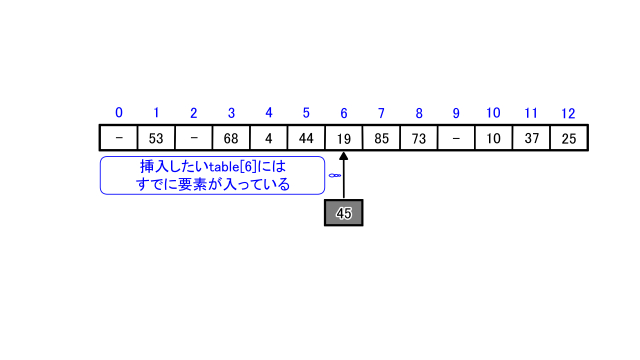
このようにバケットが重複することを衝突(collision)といいます。
通常ハッシュ関数ではハッシュ値がかぶることがほとんどです。
衝突が発生した際の解決策を考えます。
その解決策として有名なのがチェイン法です。
チェイン法
チェイン法(chaining)は同一ハッシュ値のデータをチェイン(鎖)状につなぎます。
内部で線形リストを利用することで同一ハッシュ値のデータをまとめています。
なお、チェイン法はオープンハッシュ法(open hashing)とも呼ばれています。
4、10、19、25、37、44、53、68、73、85という10個の要素がすでに昇順で格納された配列xで再度考えます。
チェイン法の仕組み
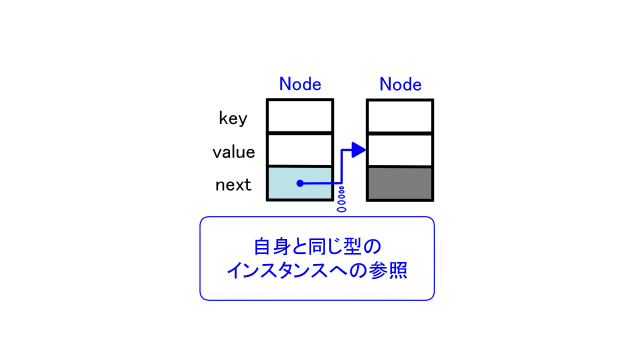
チェイン法ではノードとポインタを使ってデータの並びを表現します。
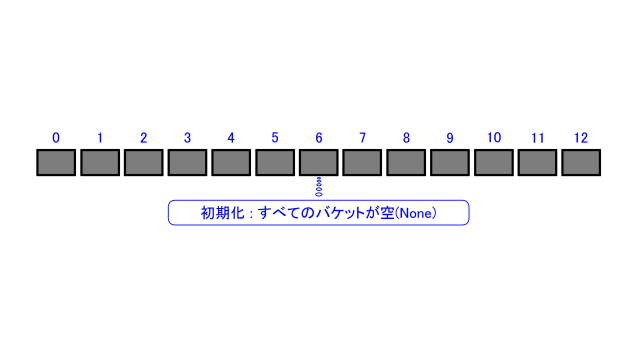
まずハッシュ表をtableとしてすべてのバケットをNoneとします。
次に各バケットに対応するキーが存在すればそのバケットがキーを参照させるようにします。
下の図は配列xの要素をチェイン法によって45を追加した後のハッシュ表を表したものです。
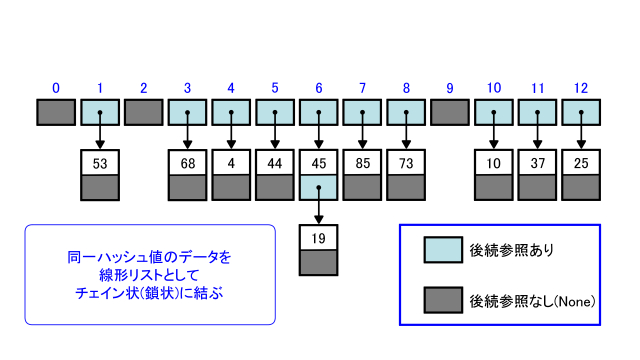
水色が参照先のノードが存在する、灰色が参照先のノードが存在しないことを表します。
table[6]にはキーが45であるノードへの参照が格納されています。
さらにキーが45であるノードにはキーである45と後続ノードにあたるキーが19であるノードへの参照が格納されています。
キーが19であるノードにはキーである19が格納されています。
ただし前方のノードとは違い後続ノードが存在しないので参照先のノードがないことを表すNoneを格納します。
なおハッシュ値が0や2や9のようにデータが1個もないバケットにはNoneを格納します。
チェイン法におけるそれぞれのバケットをプログラムで実現することを考えます。
バケット用クラスNode
# チェイン法によるハッシュ
from __future__ import annotations
from typing import Any, Type
import hashlib
class Node:
"""ハッシュを構成するノード"""
def __init__(self, key: Any, value: Any, next: Node) -> None:
"""初期化"""
self.key = key # キー
self.value = value # 値
self.next = next # 後続ノードへの参照クラスNodeには3つのフィールドがあるものとします。
| フィー ルド |
内容
型 |
|---|---|
| key | キー
任意 |
| value | 値
任意 |
| next | 後続ノードへの参照
Node型 |
クラスNodeではキーと値がペアになる構造で、キーにハッシュ関数を適応してハッシュ値を求めます。
ノードの中身を表したのが下の図です。
ハッシュクラスChainedHash
class ChainedHash:
"""チェイン法を実現するハッシュクラス"""
def __init__(self, capacity: int) -> None:
"""初期化"""
self.capacity = capacity # ハッシュ表の容量
self.table = [None] * self.capacity # ハッシュ表(すべてが空のリスト)ハッシュクラスChainedHashには2つのフィールドがあります。
| capacity | ハッシュ表tableの要素数 |
|---|---|
| table | ハッシュ表を格納する 空リスト |
仮引数capacityにハッシュ表の容量を受け取り、tableにその数をかけることでその要素数のリストが作られます。
これにより各バケットにはtable[0]からtable[capacity – 1]でアクセスできるようになります。
tableには初期値としてすべての要素にNoneを代入することによって、下の図のようにすべてのバケットが空となります。
ハッシュ関数hash_value
def hash_value(self, key: Any) -> int:
"""ハッシュ値を求める"""
if isinstance(key, int):
return key % self.capacity
return (int(hashlib.sha256(str(key).encode()).hexdigest(), 16)
% self.capacity)仮引数keyに受け取った値によってハッシュ値の求め方を分岐しています。
keyがint型
keyがint型であれば今までの例のようにkeyをcapacityで割ってハッシュ値を求めます。
keyがint型でない
keyがint型でないときは計算できる形式に変えてハッシュ値を求めるようにします。
hashlibモジュールで提供されるsha256はバイト文字列のハッシュ値を求めるアルゴリズムです。
そのためにkeyをstr型の文字列に変換してencode関数でバイト文字列にしています。
sha256アルゴリズムからのハッシュ値をhexdigestメソッドで16進文字列として取り出します。
さらにint関数でint型に変換して同じようにハッシュ値として使用できます。
キーで要素を探索search
def search(self, key: Any) -> Any:
"""キーkeyの要素の探索をして値を返却"""
hash = self.hash_value(key) # 探索するキーのハッシュ値
current = self.table[hash] # 着目ノード
while current is not None:
if current.key == key:
return current.value # 探索成功
current = current.next # 後続ノードに着目
return None # 探索失敗searchではキーがkeyである要素の探索を行います。
keyをハッシュ関数hash_valueによりハッシュ値に変換して変数hashに格納します。
hashを添え字とするバケットtable[hash]を着目ノードcurrentとします。
currentがNoneでなければ参照する線形リストが存在するので、table[hash]が参照する線形リストを先頭から順に線形探索します。
目的とするkeyと一致すればその値を返却します。
その過程で後続ノードがない、つまりcurrentがNoneであった場合は探している値がないので探索失敗です。
下の図のハッシュ表で具体的に見ていきます。
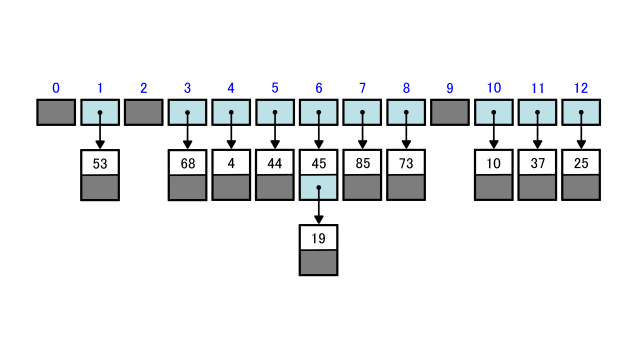
例えば19を探索するとします。
19のハッシュ値は6なのでtable[6]のノードのつながりを表す線形リストを見ます。
45から19とたどっていくと見つかるので探索成功です。
次に28を探索するとします。
28のハッシュ値は2なのでtable[2]の線形リストを見ます。
table[2]はNoneなので探索失敗です。
searchによる要素の探索の手順は以下の通りです。
| ① | ハッシュ関数によって キーをハッシュ値に変換。 |
|---|---|
| ② | 求めたハッシュ値を添え字とする バケットに着目。 |
| ③ | バケットが参照する線形リストを 先頭から順に線形探索して、 キーと同じ値があれば探索成功。 末尾に達して見つからなければ探索失敗。 |
要素を挿入するadd
def add(self, key: Any, value: Any) -> bool:
"""キーがkeyで値がvalueの要素を挿入"""
hash = self.hash_value(key) # 挿入するキーのハッシュ値
current = self.table[hash] # 着目ノード
while current is not None:
if current.key == key:
return False # 挿入失敗
current = current.next # 後続ノードに着目
add_node = Node(key, value, self.table[hash])
self.table[hash] = add_node # ノードを挿入
return True # 挿入成功addではキーがkeyで値がvalueである要素の挿入を行います。
ハッシュ関数によりハッシュ値に変換して着目ノードの添え字とするのはsearchと同じです。
以降の手続きが探索とは違います。
もしキーと同じ値が見つかれば登録済みとなり挿入できなくなるので挿入失敗となります。
それ以外では要素を挿入するのですが挿入方法も2パターンあります。
着目バケットがNone
バケットに着目してNoneであればノードを新たに生成してそのノードへの参照を着目バケットに代入します。
着目バケットがNoneではない
(すでに線形リストへの参照がある)
バケットに線形リストへの参照があればキーがないか調べます。
なければその線形リストの先頭に挿入するキーを格納したノードを新たに生成します。
そのノードへの参照を着目バケットに代入します。
さらに挿入したノードの後続ポインタnextに後ろに続くノードへの参照を代入します。
2つの具体例で解説します。
上は挿入前、下は挿入後のハッシュ表を表しています。
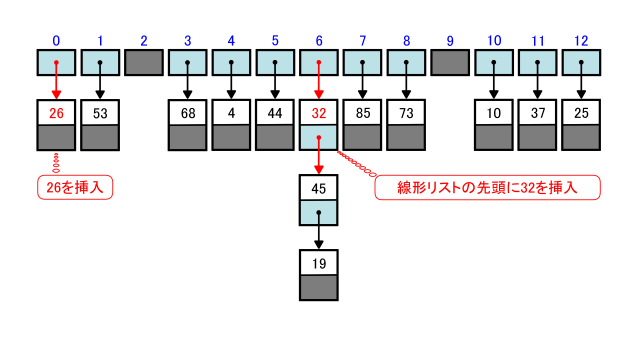
addで26を挿入します。
26のハッシュ値は0で、バケットtable[0]はNoneです。
26を格納したノードを新たに生成して、そのノードへの参照をtable[0]に代入します。
次にaddで32を挿入します。
32のハッシュ値は6で、バケットtable[6]には45と19を連結させた線形リストへの参照が格納されています。
この線形リストには32はないのでこの線形リストの先頭に32を挿入させます。
まず32を格納したノードを新たに生成して、そのノードへの参照をtable[6]に代入します。
さらに32を格納したノードの後続ポインタnextが45を格納するノードを参照するようにします。
これによりtable[6]には32、45、19の線形リストへの参照が格納させていることになります。
addによる要素の挿入の手順は以下の通りです。
| ① | ハッシュ関数によって キーをハッシュ値に変換。 |
|---|---|
| ② | 求めたハッシュ値を添え字とする バケットに着目。 |
| ③ | バケットが参照する線形リストを 先頭から順に線形探索して、 キーと同じ値があれば登録済みで挿入失敗。 末尾に達して見つからなければ 線形リストの先頭にノードを挿入。 |
要素を削除するremove
def remove(self, key: Any) -> bool:
"""キーがkeyの要素を削除"""
hash = self.hash_value(key) # 削除するキーのハッシュ値
current = self.table[hash] # 着目ノード
current.prev = None # 前回の着目ノード
while current is not None:
if current.key == key: # キーを見つけた
if current.prev is None:
self.table[hash] = current.next
else:
current.prev.next = current.next
return True # 削除成功
current.prev = current
current = current.next # 後続ノードに着目
return False # 削除失敗(keyは存在しない)removeではキーがkeyである要素の削除を行います。
ハッシュ関数によりハッシュ値に変換して着目ノードの添え字とするのはsearchやaddと同じです。
もうひとつ前回着目したノードも格納します。
着目したバケットが格納している参照先の線形リストを調べます。
そのとき、もしキーと同じ値が見つからなければ削除したい要素がないので削除失敗となります。
それ以外では要素を削除するのですが削除方法も2パターンあります。
リストが削除対象ノードのみ
ひとつは線形リストに削除するキーが格納されたノードのみがあるときです。
このときはそのノードを削除して参照先が格納されていたバケットをNoneにすれば削除完了です。
リストに削除対象ノード以外もあり
もうひとつは線形リストに削除するキーが格納されたノード以外にもノードが1個以上あるときです。
このとき、まず削除したいキーが格納されたノードを削除します。
次に削除されたノードの前にあったノードの後続ポインタに削除されたノードの後ろにあるノードを参照させるようにします。
もし前にあるのがノードではない(削除したノードが線形リストの先頭)ならバケットに参照先を代入します。
これらの手続きにより要素の削除が完了します。
下の図のハッシュ表をもとに具体例で解説します。
上は削除前、下は削除後のハッシュ表を表しています。
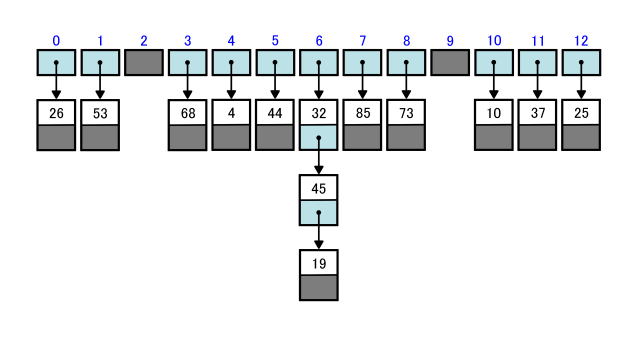
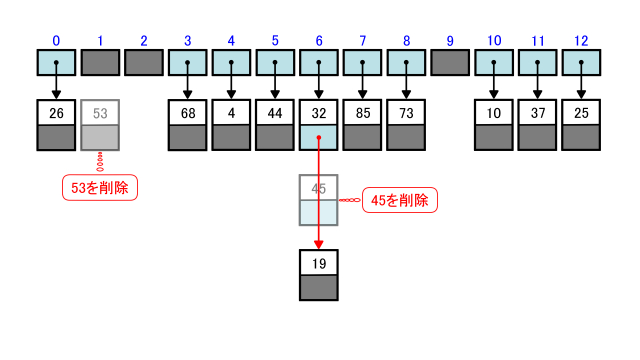
まず53を削除します。
53のハッシュ値は1なのでtable[1]の線形リストを見ると、53を格納したノード1個のみがあります。
その53を格納したノードを削除して、バケットtable[1]には参照先がないことを指すNoneを代入すれば削除完了です。
次に45を削除します。
45のハッシュ値は6なのでtable[6]の線形リストを見ます。
すると32を格納したノードと45を格納したノードと19を格納したノードの3個が連結しています。
まず削除したい45を格納したノードを削除します。
次に32を格納したノードの後続ポインタの参照先を19を格納したノードに更新します。
するとtable[6]が参照する線形リストは32を格納したノードと19を格納したノードの2個になります。
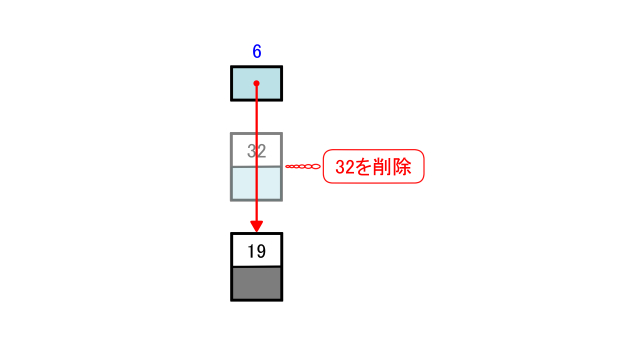
さらに32を削除します。
32のハッシュ値は6なのでtable[6]の線形リストを見ます。
すると32を格納したノードと19を格納したノードの2個が連結しています。
削除したい32を格納したノードを削除します。
次にバケットtable[6]の参照先を19を格納したノードに更新します。
するとtable[6]が参照する線形リストは19を格納したノードの1個だけになります。
これで要素の削除が完了します。
removeによる要素の削除の手順は以下の通りです。
| ① | ハッシュ関数によって キーをハッシュ値に変換。 |
|---|---|
| ② | 求めたハッシュ値を添え字とする バケットに着目。 |
| ③ | バケットが参照する線形リストを 先頭から順に線形探索して、 キーと同じ値があれば そのノードをリストから削除。 末尾に達して見つからなければ削除失敗。 |
ハッシュ表を表示するprint
def print(self) -> None:
"""ハッシュ表を表示"""
for i in range(self.capacity):
current = self.table[i]
print(i, end='')
while current is not None:
print(f' → {current.key} ({current.value})', end='')
current = current.next
print()printではハッシュ表の内容を表示します。
ハッシュ表のtable[0]からtable[capacity – 1]における線形リストを先頭から末尾まで表示します。
表示方法は線形リストを先頭から後続ノードをたどって、各ノードのキーと値を表示する処理を繰り返します。
同一ハッシュ値のノードがどのように並んでいるかがわかるように矢印記号で表しました。
チェイン法によるハッシュのプログラムは以下の通りです。
チェイン法によるハッシュのプログラム
# チェイン法によるハッシュ
from __future__ import annotations
from typing import Any, Type
import hashlib
class Node:
"""ハッシュを構成するノード"""
def __init__(self, key: Any, value: Any, next: Node) -> None:
"""初期化"""
self.key = key # キー
self.value = value # 値
self.next = next # 後続ノードへの参照
class ChainedHash:
"""チェイン法を実現するハッシュクラス"""
def __init__(self, capacity: int) -> None:
"""初期化"""
self.capacity = capacity # ハッシュ表の容量
self.table = [None] * self.capacity # ハッシュ表(すべてが空のリスト)
def hash_value(self, key: Any) -> int:
"""ハッシュ値を求める"""
if isinstance(key, int):
return key % self.capacity
return (int(hashlib.sha256(str(key).encode()).hexdigest(), 16)
% self.capacity)
def search(self, key: Any) -> Any:
"""キーkeyの要素の探索をして値を返却"""
hash = self.hash_value(key) # 探索するキーのハッシュ値
current = self.table[hash] # 着目ノード
while current is not None:
if current.key == key:
return current.value # 探索成功
current = current.next # 後続ノードに着目
return None # 探索失敗
def add(self, key: Any, value: Any) -> bool:
"""キーがkeyで値がvalueの要素を挿入"""
hash = self.hash_value(key) # 挿入するキーのハッシュ値
current = self.table[hash] # 着目ノード
while current is not None:
if current.key == key:
return False # 挿入失敗
current = current.next # 後続ノードに着目
add_node = Node(key, value, self.table[hash])
self.table[hash] = add_node # ノードを挿入
return True # 挿入成功
def remove(self, key: Any) -> bool:
"""キーがkeyの要素を削除"""
hash = self.hash_value(key) # 削除するキーのハッシュ値
current = self.table[hash] # 着目ノード
current.prev = None # 前回の着目ノード
while current is not None:
if current.key == key: # キーを見つけた
if current.prev is None:
self.table[hash] = current.next
else:
current.prev.next = current.next
return True # 削除成功
current.prev = current
current = current.next # 後続ノードに着目
return False # 削除失敗(keyは存在しない)
def print(self) -> None:
"""ハッシュ表を表示"""
for i in range(self.capacity):
current = self.table[i]
print(i, end='')
while current is not None:
print(f' → {current.key} ({current.value})', end='')
current = current.next
print()このプログラムは「chained_hash.py」という名前で保存してください。
チェイン法によるハッシュを利用するプログラム
コード例
# チェイン法を実現するハッシュクラスChainedHashの利用例
from enum import Enum
from chained_hash import ChainedHash
Menu = Enum('Menu', ['追加', '削除', '探索', '表示', '終了'])
def select_menu() -> Menu:
"""メニュー選択"""
s = [f'({m.value}){m.name}' for m in Menu]
while True:
print(*s, sep=' ', end='')
n = int(input(' : '))
if 1 <= n <= len(Menu):
return Menu(n)
hash = ChainedHash(13) # 容量13のハッシュ表
while True:
menu = select_menu() # メニュー選択
if menu == Menu.追加: # 追加
add_key = int(input('キー : '))
add_value = input('値 : ')
if not hash.add(add_key, add_value):
print('追加できませんでした。')
elif menu == Menu.削除: # 削除
remove_key = int(input('キー : '))
if not hash.remove(remove_key):
print('削除できませんでした。')
elif menu == Menu.探索: # 探索
search_key = int(input('キー : '))
search_value = hash.search(search_key)
if search_value is not None:
print(f'そのキーの値は{search_value}です。')
else:
print('そのキーにデータはありませんでした。')
elif menu == Menu.表示: # 表示
hash.print()
else: # 終了
break実行結果
(1)追加 (2)削除 (3)探索 (4)表示 (5)終了 : 1
キー : 2
値 : 吉川
(1)追加 (2)削除 (3)探索 (4)表示 (5)終了 : 1
キー : 6
値 : 坂本
(1)追加 (2)削除 (3)探索 (4)表示 (5)終了 : 1
キー : 8
値 : 丸
(1)追加 (2)削除 (3)探索 (4)表示 (5)終了 : 1
キー : 10
値 : 中田
(1)追加 (2)削除 (3)探索 (4)表示 (5)終了 : 1
キー : 21
値 : 井納
(1)追加 (2)削除 (3)探索 (4)表示 (5)終了 : 3
キー : 6
そのキーの値は坂本です。
(1)追加 (2)削除 (3)探索 (4)表示 (5)終了 : 4
0
1
2 → 2 (吉川)
3
4
5
6 → 6 (坂本)
7
8 → 21 (井納) → 8 (丸)
9
10 → 10 (中田)
11
12
(1)追加 (2)削除 (3)探索 (4)表示 (5)終了 : 2
キー : 21
(1)追加 (2)削除 (3)探索 (4)表示 (5)終了 : 4
0
1
2 → 2 (吉川)
3
4
5
6 → 6 (坂本)
7
8 → 8 (丸)
9
10 → 10 (中田)
11
12
(1)追加 (2)削除 (3)探索 (4)表示 (5)終了 : 5このプログラムは「chained_hash_test.py」という名前で「chained_hash.py」と同じフォルダに保存してください。